Do Log-Log ao Causal ML: Como Escolher o Modelo de Elasticidade Certo Para Cada Produto
Artigo elaborado pelo sócio Anderson Correia
Pesquisas da NielsenIQ e da IRI mostram que, na maioria das categorias de bens de consumo, a elasticidade-preço varia entre -1,2 e -2,4, com casos extremos chegando a -2,8 em commodities e -0,7 em marcas premium consolidadas. São faixas amplas, e a diferença entre um extremo e outro pode representar dezenas de pontos-base de margem em uma decisão de reajuste.
O problema: a maioria das empresas aplica o mesmo modelo para todos os SKUs do portfólio.
Uma empresa com 800 SKUs entre commodities, itens intermediários e produtos premium usa, em geral, um único modelo Log-Log calibrado na base agregada e depois aplica a elasticidade resultante para simular o impacto de qualquer variação de preço, em qualquer produto. O modelo entrega um número. O número alimenta a decisão.
O que ninguém pergunta é: esse número é o mais adequado para este produto, neste momento de mercado?
O Problema: Elasticidade Constante Como Ponto Cego
O modelo Log-Log, a especificação `ln(Q) = α + ε · ln(P)` tem uma propriedade matematicamente conveniente: o coeficiente `ε` é a elasticidade. Isso simplifica a interpretação e garante que o modelo nunca preveja volumes negativos, o que o torna robusto para uso operacional.
Bolton (1989) demonstrou, em estudo seminal no Journal of Retailing, que o Log-Log é consistentemente mais robusto do que a regressão linear para dados de varejo, e essa conclusão se manteve em décadas de validações posteriores. Não é por acaso que virou padrão.
Mas há um custo embutido nessa conveniência: o modelo assume que a sensibilidade ao preço é constante ao longo de toda a faixa de preços. Para um produto que opera em uma banda estreita de preço com demanda estável, essa simplificação é aceitável. Para um produto premium que atravessa diferentes segmentos de consumidores conforme o preço varia, ou para um item que tem um patamar psicológico claro onde a demanda muda de comportamento, essa simplificação introduz erro sistemático.
Em projetos de estimação de elasticidade com dados de sell-in/sell-out, o modelo Log-Log tende a subestimar a elasticidade de SKUs no quartil superior de preço da categoria em média 18 a 25% em comparação com abordagens que permitem não-linearidade. O modelo não está “errado”. Ele apenas captura uma curva diferente da que o produto realmente descreve.
A Progressão de Modelos: Cinco Abordagens e Quando Usar Cada Uma
A recomendação estratégica não é substituir o Log-Log. É saber quando ele é suficiente e quando não é.
1. Modelo Linear (Level-Level)
Q = α + β · P
Elasticidade pontual: E = β · (P / Q)
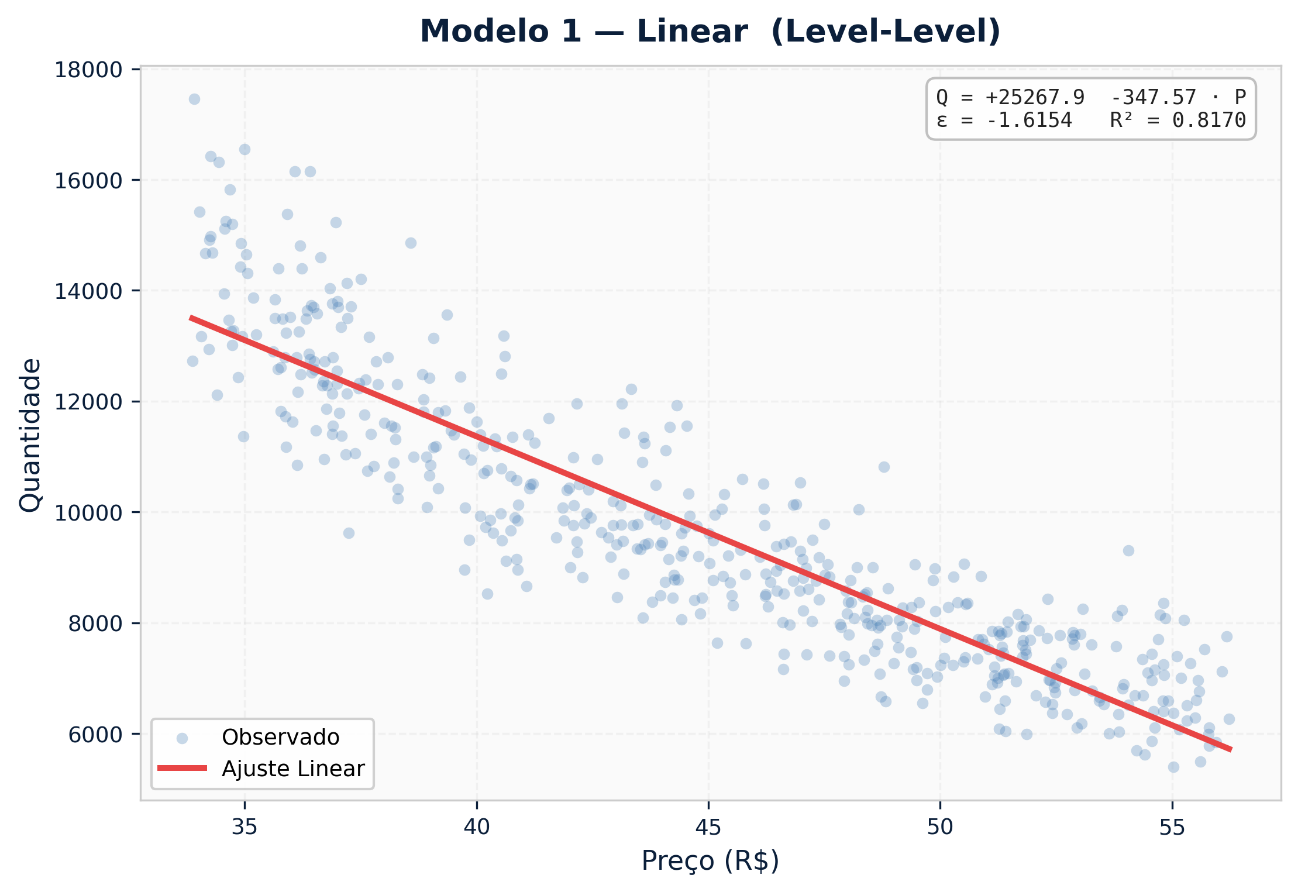
A forma mais simples. O coeficiente `β` indica quantas unidades são perdidas ou ganhas por cada unidade monetária de variação de preço.
Quando usar: Produtos com variação de preço pequena e demanda muito estável no curto prazo. Útil como linha de base para comparação.
Limitação: Pode prever volumes negativos em preços extremos. A elasticidade varia conforme o preço e a quantidade — o que torna difícil comparar entre SKUs.
2. Modelo Log-Log (Elasticidade Constante) — O Padrão de Mercado
ln(Q) = α + ε · ln(P)
Elasticidade: E = ε (constante)
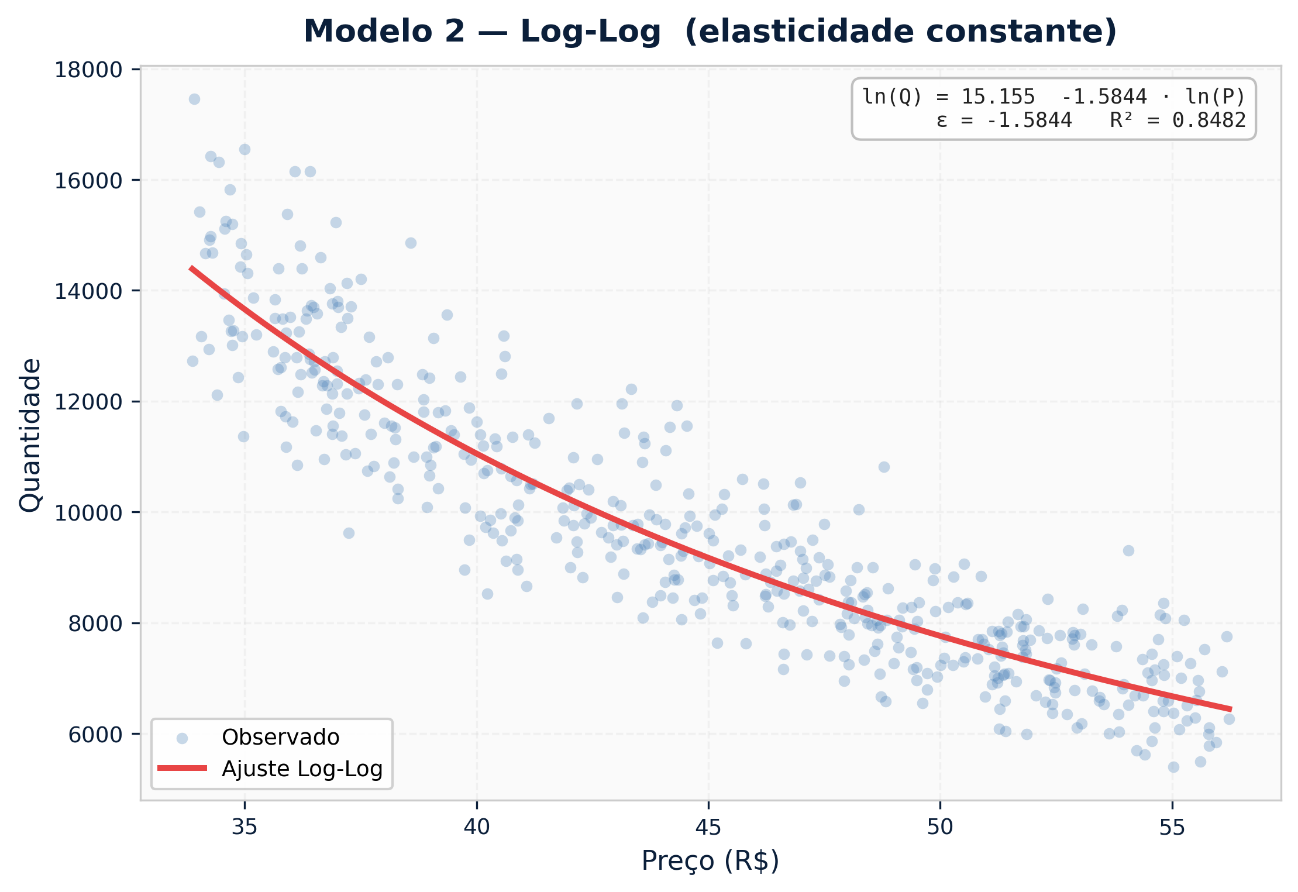
A elasticidade é o próprio coeficiente. Se `ε = -1,5`, um aumento de 1% no preço reduz a demanda em 1,5%, independentemente do nível de preço atual.
Quando usar: Benchmarking, comparações entre categorias, produtos com demanda estável e faixa de preço moderada. É o modelo padrão para a maioria dos projetos de elasticidade em FMCG e varejo.
Limitação: Assume elasticidade constante. Não captura mudanças de comportamento em patamares de preço críticos (luxo, commodity, pontos psicológicos).
3. Regressão Polinomial — Capturando Curvaturas
Q = α + β₁ · P + β₂ · P²
Elasticidade: E = (β₁ + 2β₂ · P) · (P / Q)
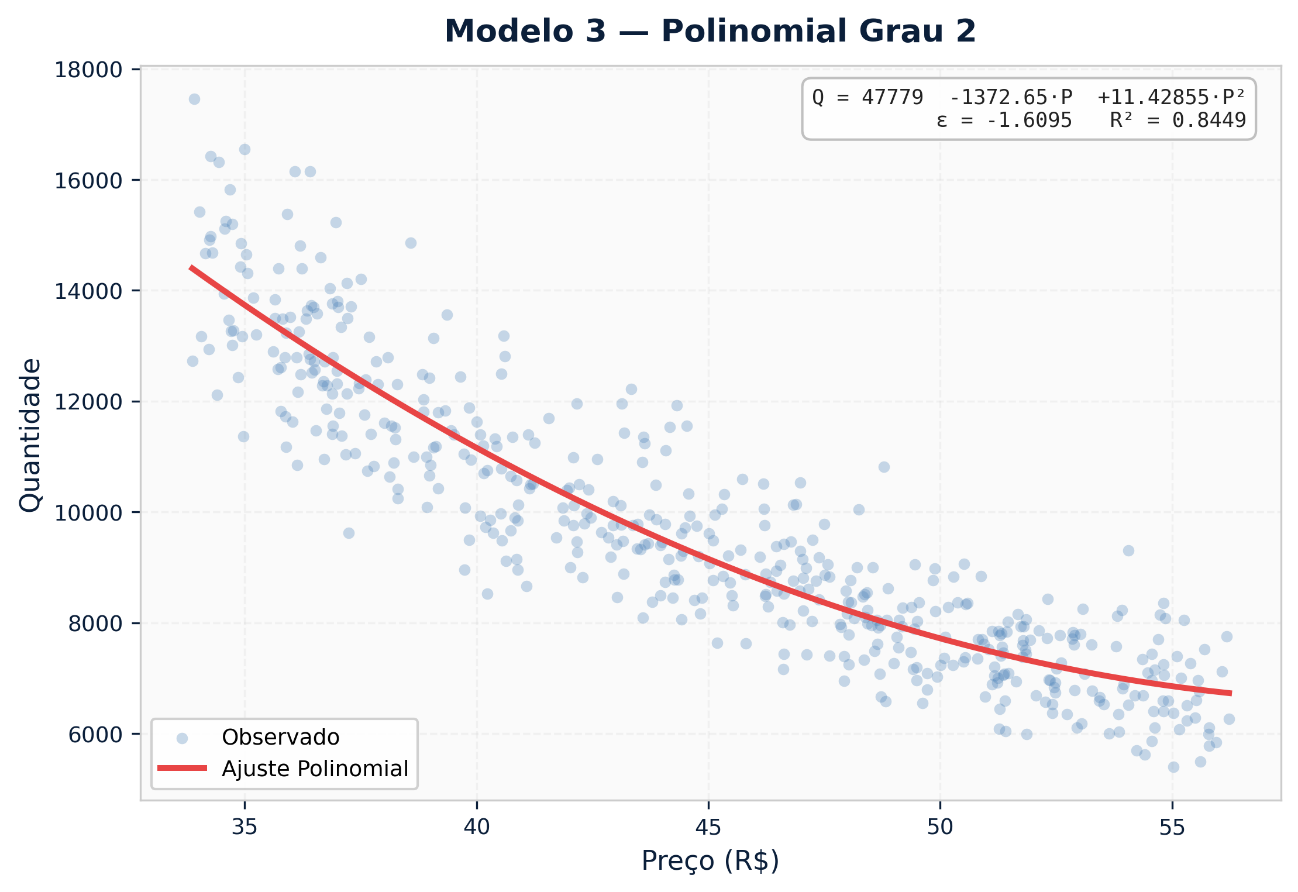
Permite que a sensibilidade ao preço acelere ou desacelere conforme o preço sobe. Pode identificar pontos de ruptura, níveis de preço onde a queda de demanda se torna significativamente mais acentuada.
Quando usar: Produtos com faixa de preço ampla ou histórico de variações relevantes. Categorias onde se suspeita de patamares psicológicos.
Limitação: Risco de overfitting com bases de dados pequenas. O grau do polinômio precisa ser validado com cuidado.
4. Modelos Logit e Price-Range Logit — Perspectiva Probabilística
O Logit clássico modela a probabilidade de escolha de um produto em função do preço:
P(escolha) = 1 / (1 + exp(-(α + β · Preço)))
Elasticidade: E = β · Preço · (1 – P(escolha))
É o modelo mais adequado para análises a nível de transação individual ou para entender substituição entre marcas em ambientes competitivos.
Adaptação prática — Price-Range Logit:
Uma extensão relevante para dados de vendas agregadas define os limites históricos de preço do SKU (`P_min` e `P_max`) e normaliza o preço nessa faixa:
P_norm = (Preço – P_min) / (P_max – P_min) ∈ [0, 1]
P(demanda_alta) = σ(α + β · P_norm)
Elasticidade: E = β · (1 / (P_max – P_min)) · Preço · (1 – P̂)
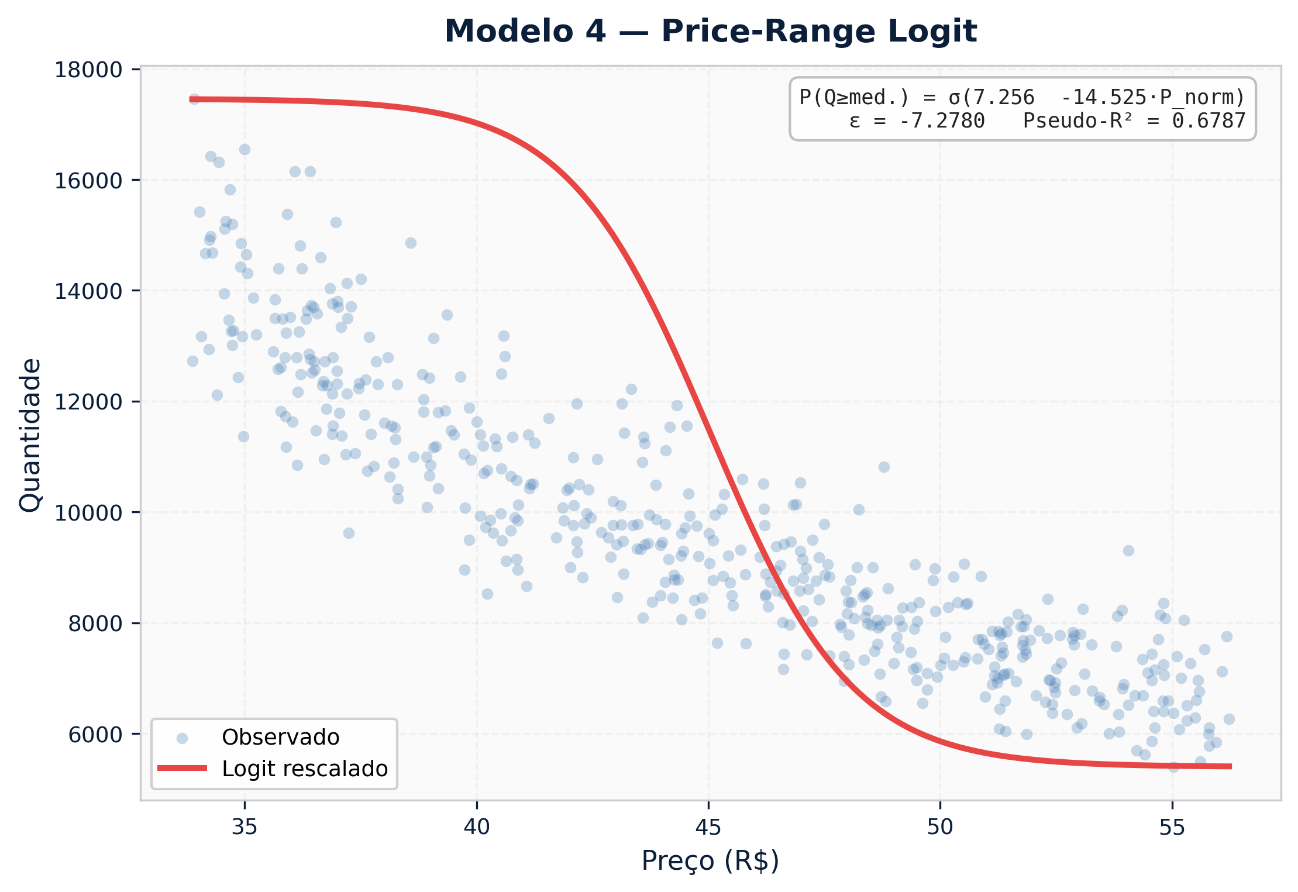
Essa adaptação resolve um problema prático comum: a comparação de elasticidades entre SKUs com escalas de preço muito diferentes (um item de R$ 8,00 vs. um de R$ 3.200,00). O modelo normalizado define naturalmente um teto de resistência (P_max) e um piso de aceitação (P_min), permitindo estimar em qual percentil da faixa de preço a demanda começa a cair de forma relevante.
Quando usar: Portfólios com grande heterogeneidade de preços, análises de posicionamento relativo, produtos onde a percepção de “caro” ou “barato” é relativa ao histórico da categoria.
5. Machine Learning Supervisionado — Árvore de Decisão, Random Forest, XGBoost e Redes Neurais
Os modelos de ML supervisionado abordam a estimação de elasticidade de forma fundamentalmente diferente dos modelos econométricos clássicos: em vez de impor uma forma funcional (linear, log-log, polinomial), deixam os dados definirem a relação entre preço e quantidade — capturando interações, não linearidades e efeitos de contexto que os modelos paramétricos não conseguem representar.
A elasticidade nesses modelos não é um coeficiente direto. Ela é calculada via diferenciação numérica parcial: perturba-se o preço em δ (ex: +1%), mantendo todas as outras variáveis fixas, e observa-se a resposta prevista do modelo.
E ≈ [f(P + δ, X) – f(P, X)] / [f(P, X)] ÷ (δ / P)
Onde `f(P, X)` é a previsão do modelo para o preço `P` dado o vetor de covariáveis `X`.
5.1 Árvore de Decisão (Decision Tree)
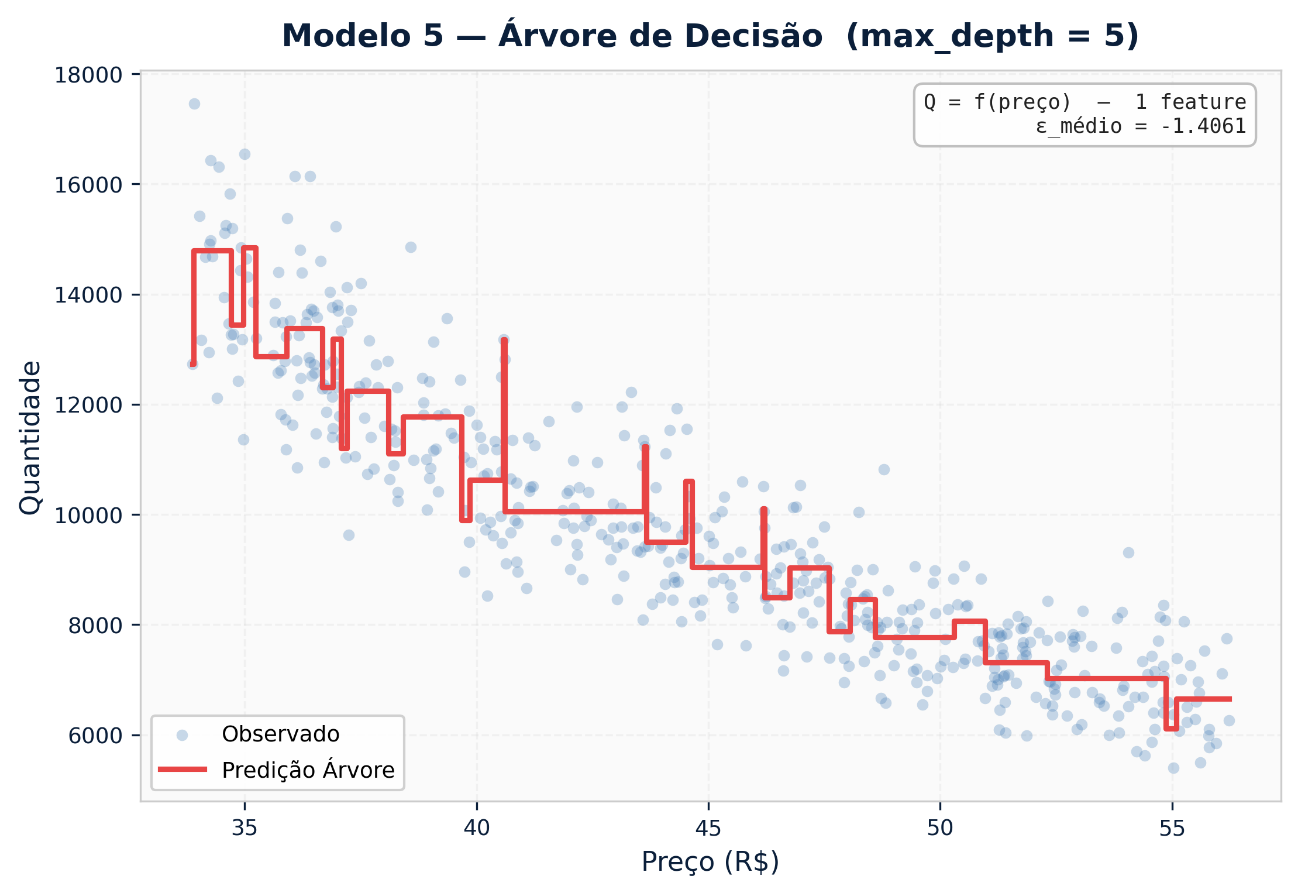
Particiona o espaço de variáveis em regiões retangulares através de splits binários. A elasticidade resultante é constante dentro de cada folha, o que significa que o modelo captura descontinuidades (patamares de preço onde o comportamento muda abruptamente), mas não transições suaves.
Elasticidade na folha k:
E_k = [Q_k(P + δ) – Q_k(P)] / Q_k(P) ÷ (δ / P)
Quando usar: Diagnóstico exploratório para identificar segmentos de preço com comportamento distinto. Útil para descobrir pontos de ruptura antes de modelar com abordagens mais sofisticadas.
Limitação: Alta variância. Árvores únicas são instáveis e tem overfit facilmente. Não usar como modelo final de produção sem ensemble.
5.2 Random Forest
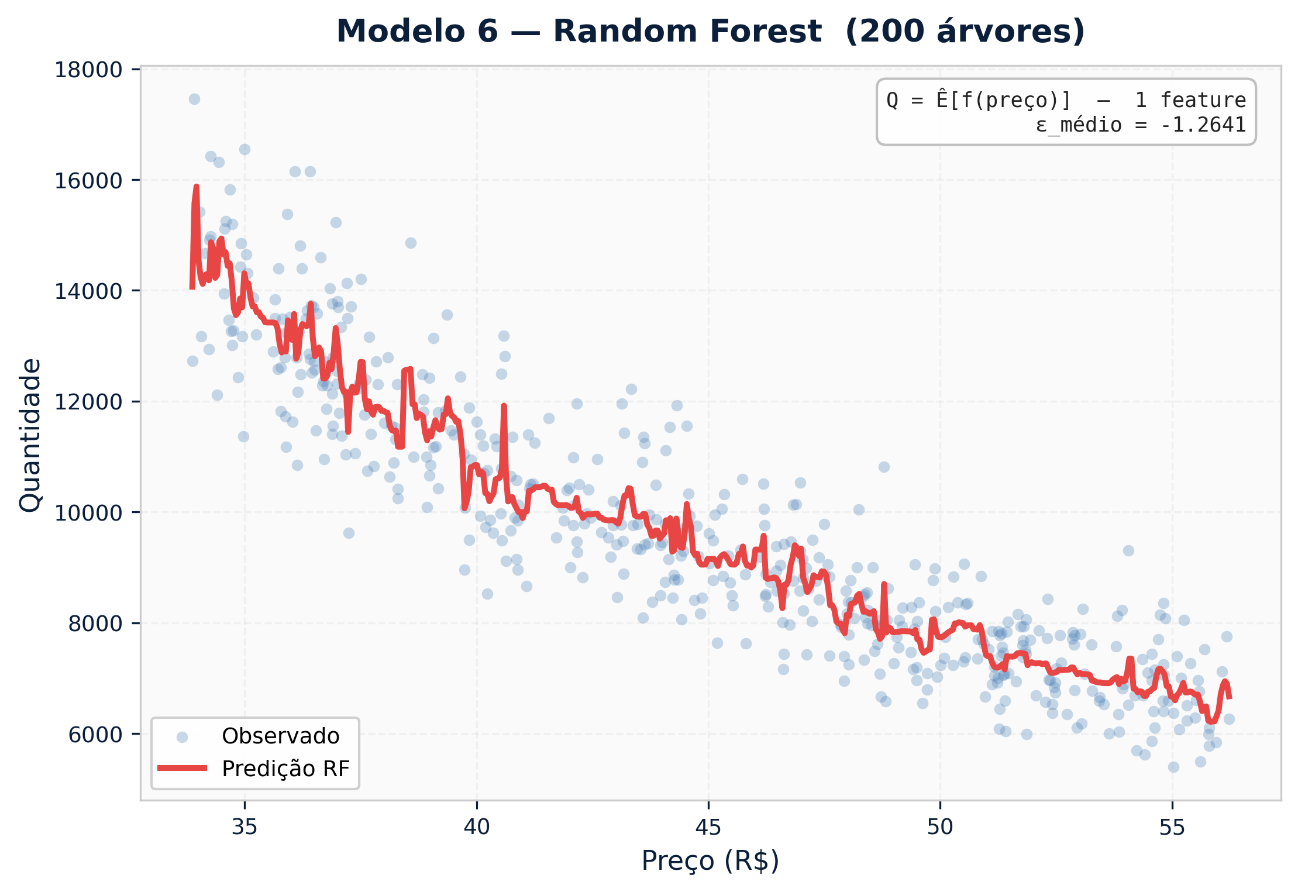
Ensemble de centenas de árvores treinadas em subamostras aleatórias dos dados e das variáveis. A elasticidade é a média das elasticidades individuais de cada árvore, o que reduz a variância e estabiliza as estimativas.
A importância de variáveis (feature importance por impureza ou por permutação) permite identificar quais fatores de contexto mais modulam a elasticidade: promoções de concorrentes, nível de estoque, sazonalidade, canal de venda.
Quando usar: Portfólios com muitas variáveis de contexto e histórico suficiente (>18 meses). Quando se quer entender quais fatores tornam um SKU mais ou menos sensível ao preço em diferentes momentos.
Limitação: Elasticidades podem ser instáveis em faixas de preço com poucos dados históricos (efeito escada nas previsões). O modelo não extrapola bem fora da faixa de preços observada no treino.
5.3 XGBoost (Gradient Boosting)
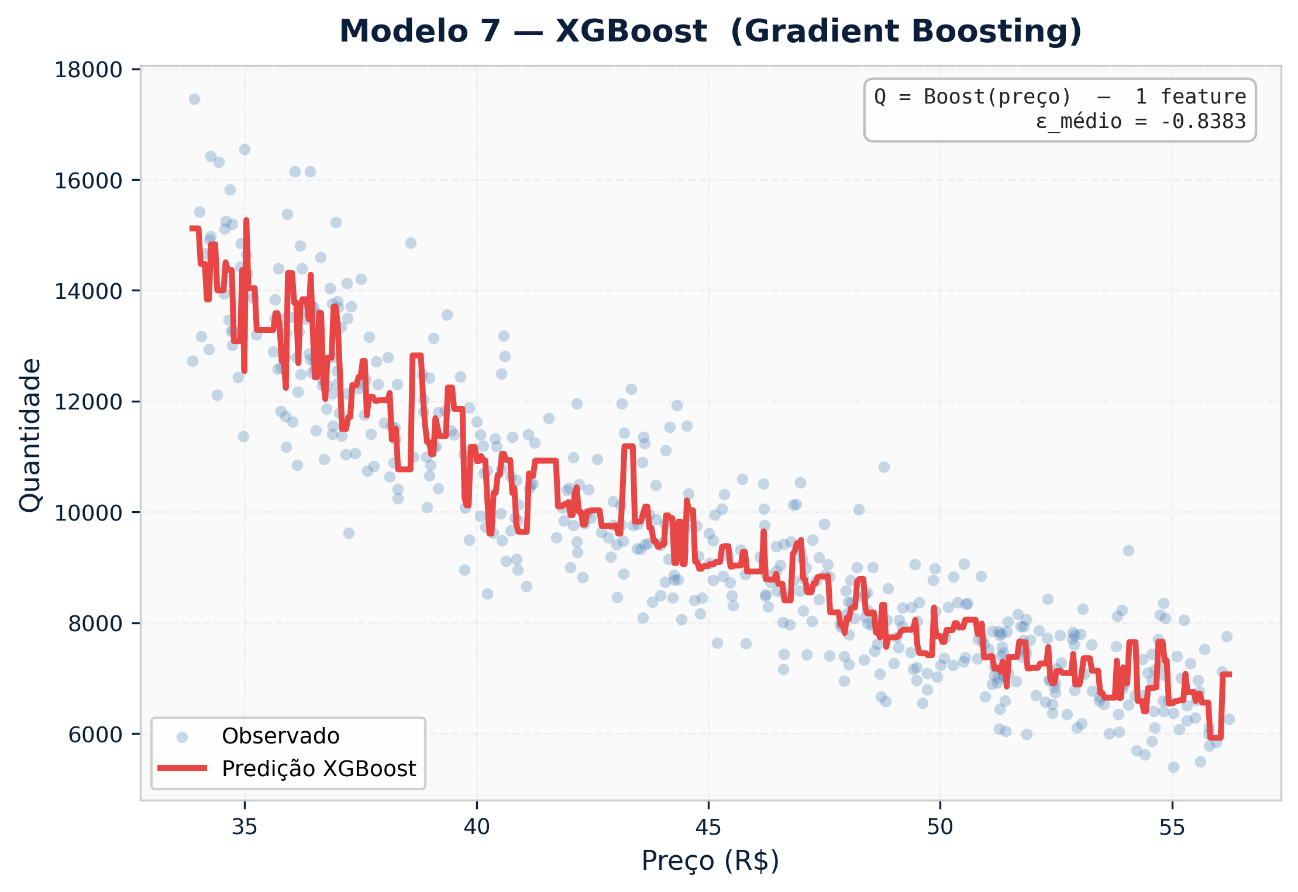
Constrói árvores sequencialmente, cada uma corrigindo o erro residual da anterior. É consistentemente o modelo com melhor desempenho preditivo em dados tabulares de varejo e FMCG — e por isso o mais usado em produção para forecasting de demanda.
Para elasticidade, a vantagem do XGBoost sobre o Random Forest é a capacidade de capturar assimetrias: a resposta da demanda a um aumento de preço pode ser diferente em magnitude da resposta a uma redução equivalente, e o gradient boosting detecta esse padrão com mais precisão.
Quando usar: Pipeline de produção com retraining periódico. Quando a precisão preditiva é crítica e há dados suficientes para validação cruzada temporal (walk-forward).
Limitação: Interpretabilidade reduzida. Requer monitoramento ativo de data drift — a elasticidade estimada muda conforme o modelo é retrainado com novos dados.
5.4 Redes Neurais (MLP / LSTM)
As redes neurais densas (MLP — Multi-Layer Perceptron) aproximam funções arbitrariamente complexas e são capazes de capturar interações de alta ordem entre variáveis. Para séries temporais de preço e demanda, redes recorrentes como LSTM (Long Short-Term Memory) capturam dependências temporais de longo prazo — o efeito de preços praticados há 3 ou 6 meses sobre a demanda atual.
A elasticidade via MLP é calculada pela derivada parcial analítica em relação ao preço (quando a ativação é diferenciável):
∂Q/∂P = produto das derivadas ao longo das camadas (backpropagation)
E = (∂Q/∂P) · (P / Q)
Quando usar: Altíssima escala de dados (e-commerce com milhões de transações diárias), precificação dinâmica onde o contexto temporal é essencial, categorias com sazonalidade complexa e múltiplos ciclos sobrepostos.
Limitação: Requerem grandes volumes de dados para convergir, são custosas computacionalmente e têm interpretabilidade baixa. O risco de overfitting é alto sem regularização adequada (Dropout, L2, early stopping). Para a maioria dos projetos de pricing B2B e FMCG com dados mensais ou semanais, XGBoost entrega resultados equivalentes com muito menos custo operacional.
Nota sobre intervalo de confiança em modelos de ML:
Ao contrário dos modelos econométricos, modelos de ML padrão não produzem intervalos de confiança nativamente. As principais abordagens para quantificar incerteza são: (1) Quantile Regression com XGBoost ou LightGBM — treina modelos separados para os percentis P10, P50 e P90; (2) Bootstrap — reamostrar os dados de treino N vezes e calcular o desvio-padrão das elasticidades estimadas; (3) Conformal Prediction— abordagem mais recente que fornece garantias de cobertura sem suposições distribucionais.
6. Inferência Causal — Double Machine Learning (DML)
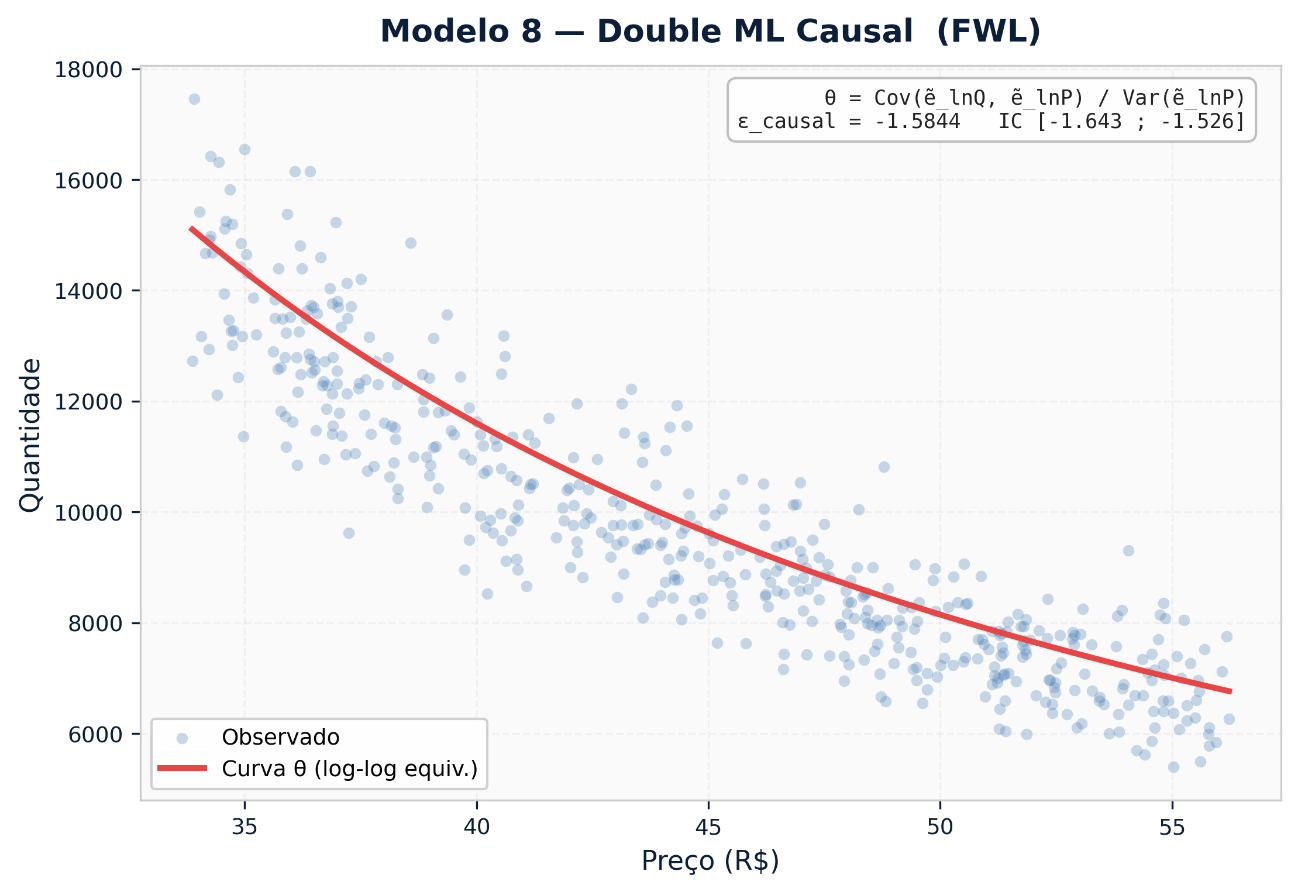
O problema das abordagens preditivas da Seção 5 para estimação de elasticidade é a endogeneidade: preços sobem quando há pressão de custos e caem durante promoções, padrões que se confundem com a resposta real da demanda. Um modelo treinado para prever vendas captura correlações históricas, não o efeito causal do preço.
O Double Machine Learning (DML), formalizado por Chernozhukov et al. (2018) no Econometrics Journal, resolve esse problema ao residualizar tanto o preço quanto a quantidade em relação às variáveis de confundimento (sazonalidade, custos, ações de marketing) e, em seguida, estimar o efeito causal a partir dos resíduos ortogonalizados. O resultado é a medida mais próxima do efeito direto do preço sobre a demanda, isolado de tudo que acontece ao mesmo tempo.
Modelo 1: Preço ~ f(contexto) → resíduo de preço (ẽ_P)
Modelo 2: Quantidade ~ g(contexto) → resíduo de quantidade (ẽ_Q)
Elasticidade causal: θ = Cov(ẽ_Q, ẽ_P) / Var(ẽ_P)
Quando usar: Bases de dados ricas (pelo menos 2 anos de histórico com variabilidade real de preços), ambientes com muitas variáveis confundidoras, decisões estratégicas de longo prazo onde o viés de correlação pode distorcer o planejamento.
Limitação: Alta demanda de dados e capacidade técnica. Elasticidades geradas por ML podem ser instáveis em faixas de preço com poucos dados históricos.
Nuances e Limitações: O Que Nenhum Modelo Resolve Sozinho
Três pontos que frequentemente ficam fora da análise:
1. Endogeneidade é quase universal em dados observacionais. Preços não variam aleatoriamente. Eles respondem a custos, concorrência e demanda. Qualquer modelo que ignore isso estima correlação, não causalidade. O Log-Log padrão, sem instrumentos ou residualização, está sujeito a esse viés.
2. Elasticidade não é estável no tempo. O comportamento do consumidor muda com inflação, recessão, entrada de novos concorrentes e mudanças de canal. Um modelo calibrado em 2021 pode gerar previsões sistematicamente erradas em 2024. Recalibração periódica não é opcional. É manutenção básica.
3. Precisão estatística não é suficiência gerencial. Um modelo com R² alto pode ainda ser inadequado para suporte à decisão se a faixa de variação de preço na base histórica for muito pequena. A extrapolação fora da faixa observada é um risco real que nenhum índice de ajuste sinaliza automaticamente.
Esse processo de Build (construir a capacidade analítica), Operate (rodar e validar os modelos) e Transfer (disseminar o conhecimento para a equipe de pricing) é o que diferencia uma empresa que “tem elasticidade” de uma que “entende elasticidade”.
Praticidade e Evolução Gradual
Percorrer seis, sete ou oito abordagens de modelagem em uma única leitura pode gerar uma impressão equivocada: a de que existe uma hierarquia rígida onde modelos mais complexos são superiores aos mais simples. Não é assim que funciona na prática.
Não há modelo certo ou errado. Há o modelo adequado ao nível de maturidade da equipe, à qualidade dos dados disponíveis e à clareza da pergunta que se quer responder.
O Log-Log não é um modelo “para iniciantes” que deve ser descartado assim que a equipe ganha experiência. Ele é o ponto de referência. É ele que permite dizer, com precisão, que o XGBoost ou o DML estimou uma elasticidade 18% maior — e que essa diferença importa para um determinado SKU. Sem o Log-Log como base, não há comparação possível.
O mesmo vale para a Árvore de Decisão: usada como diagnóstico exploratório, ela revela partições de preço que justificam modelos mais sofisticados. Ignorá-la por ser “simples demais” é abrir mão de um instrumento de leitura rápida que nenhum modelo mais complexo substitui com a mesma transparência.
O critério central: interpretabilidade
A chave para qualquer decisão de pricing não é a precisão estatística do modelo — é a capacidade do gestor ou analista de entender o que o modelo está dizendo e por quê. Um modelo que produz uma elasticidade de -1,85 mas cuja lógica interna é opaca para quem vai tomar a decisão de reajuste não é mais útil do que um modelo com -1,50 que a equipe consegue questionar, contestar e refinar.
Isso tem uma consequência prática importante: a escolha do modelo deve levar em conta não apenas o ajuste técnico, mas o grau de confiança que a equipe deposita na interpretação do resultado. Um XGBoost com R² de 0,91 e um coeficiente de elasticidade que ninguém sabe explicar para o diretor comercial é, na prática, menos útil do que um Log-Log com R² de 0,78 que gera uma conversa produtiva sobre precificação.
A progressão é gradual — e cada passo precisa ser operado antes de ser superado
A evolução natural é:
Log-Log (entender a base)
→ Polinomial ou Logit (testar não-linearidades em SKUs-chave)
→ Random Forest / XGBoost (incorporar contexto)
→ DML (isolar causalidade quando os dados permitem)
Cada degrau só faz sentido se o degrau anterior foi compreendido, operado com sucesso e documentado. Uma empresa que pula do Log-Log direto para XGBoost sem ter calibrado e validado o modelo mais simples tende a acumular complexidade sem ganho real de entendimento, e, pior, sem capacidade de identificar quando o modelo mais avançado está errando.
A maturidade em elasticidade não se mede pelo sofisticação do modelo em produção. Mede-se pela capacidade da equipe de escolher o modelo certo para cada contexto — e de explicar essa escolha.
Reflexão Final
A maioria das equipes de pricing sabe que usa Log-Log. Poucas sabem por que usam Log-Log, e ainda menos testaram se é a forma funcional mais adequada para os produtos que realmente definem a margem da empresa.
Qual modelo sua equipe aplica hoje para os SKUs de maior contribuição marginal — e você já validou se ele é o mais adequado para a faixa de preço em que esses produtos operam?
Referências
1. Bolton, R.N. (1989). “The Robustness of Retail-Level Price Elasticity Estimates.”Journal of Retailing, 65(2), 193–219.
2. Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., Robins, J. (2018). “Double/Debiased Machine Learning for Treatment and Structural Parameters.”The Econometrics Journal, 21(1), C1–C68. DOI: 10.1111/ectj.12097
3. NielsenIQ / IRI (2021–2023). Benchmarks setoriais de elasticidade-preço em FMCG. Referência: faixa típica de -1,2 a -2,4 (maioria das categorias), com extremos de -0,7 a -2,8.
4. Zornig, F. (Professional Pricing Society). “Understanding Price Elasticity Models: A Comprehensive Guide.” PPS Pricing Article Archives.


